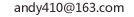准确率(Accuracy) | 查准率(Precision) | 查全率(Recall)
在机器学习中,对于一个模型的性能评估是必不可少的。准确率(Accuracy)、查准率(Precision)、查全率(Recall)是常见的基本指标。
为了方便说明,假设有以下问题场景:
要了解这些指标的含义,首先需要了解两种样本:
于是我们可以得到下面一张表:
有了上述知识,就可以计算各种指标了。
分类正确的样本数 与 样本总数之比。即: (TP + TN) / ( ALL ) .
在本例中,正确分类了45人(及格37 + 不及格8),所以 Accuracy = 45 / 50 = 90% .
被正确检索的样本数 与 被检索到样本总数之比。即: TP / (TP + FP) .
在本例中,正确检索到了37人,总共检索到39人,所以 Precision = 37 / 39 = 94.9% .
被正确检索的样本数 与 应当被检索到的样本数之比。即: TP / (TP + FN) .
在本例中,正确检索到了37人,应当检索到40人,所以 Recall = 37 / 40 = 92.5% .
根据上边公式的不同,可以借此理解不同指标的意义。
准确率 是最常用的指标,可以总体上衡量一个预测的性能。但是某些情况下,我们也许会更偏向于其他两种情况。
「宁愿漏掉,不可错杀」
在识别垃圾邮件的场景中可能偏向这一种思路,因为我们不希望很多的正常邮件被误杀,这样会造成严重的困扰。
因此,Precision 将是一个被侧重关心的指标。
「宁愿错杀,不可漏掉」
在金融风控领域大多偏向这种思路,我们希望系统能够筛选出所有有风险的行为或用户,然后交给人工鉴别,漏掉一个可能造成灾难性后果。
因此,Recall 将是一个被侧重关心的指标。
更多时候,我们希望能够同时参考 Precision 与 Recall,但又不是像 Accuracy 那样只是泛泛地计算准确率,此时便引入一个新指标 F-Score ,用来综合考虑 Precision 与 Recall.
其中 β 用于调整权重,当 β=1 时两者权重相同,简称为 F1-Score .
若认为 Precision 更重要,则减小 β,若认为 Recall 更重要,则增大 β.